MySQL 字符集与排序规则陷阱
字符集问题经常在系统国际化或多语言支持时暴露,处理不当会导致乱码、排序错误、索引失效。
为什么字符集如此重要?
不同的字符集支持不同的字符范围,排序规则影响字符串比较和排序结果。
示例场景
SQL
-- 查看字符集配置
SHOW VARIABLES LIKE 'character_set%';
SHOW VARIABLES LIKE 'collation%';
-- 雷区:UTF8不是真正的UTF-8
-- MySQL的utf8最多支持3字节,无法存储emoji等4字节字符
CREATE TABLE user_utf8 (
id INT PRIMARY KEY,
name VARCHAR(50) CHARACTER SET utf8
);
-- 插入emoji表情失败
INSERT INTO user_utf8 VALUES (1, '张三😊'); -- 错误!
-- 正确:使用utf8mb4
CREATE TABLE user_utf8mb4 (
id INT PRIMARY KEY,
name VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci
);
-- 插入emoji成功
INSERT INTO user_utf8mb4 VALUES (1, '张三😊'); -- 成功!
-- 雷区:排序规则影响查询结果
CREATE TABLE product (
id INT PRIMARY KEY,
name VARCHAR(100)
) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
-- 大小写不敏感查询
SELECT * FROM product WHERE name = 'apple'; -- 会匹配'Apple', 'APPLE'
-- 如果需要大小写敏感,使用binary或特定collation
SELECT * FROM product WHERE name = BINARY 'apple'; -- 只匹配'apple'3. 深度剖析
有些小伙伴在工作中可能遇到过存储emoji失败,或者查询时大小写匹配异常,这都是字符集配置不当导致的。
3.1 UTF8 vs UTF8MB4:
utf8:MySQL历史上的"假UTF-8",最多3字节,不支持emoji、部分中文生僻字 utf8mb4:真正的UTF-8实现,支持4字节,推荐使用
3.2 排序规则的影响:
_ci结尾:大小写不敏感(Case Insensitive)
_cs结尾:大小写敏感(Case Sensitive)
_bin结尾:二进制比较,完全匹配
对比图: 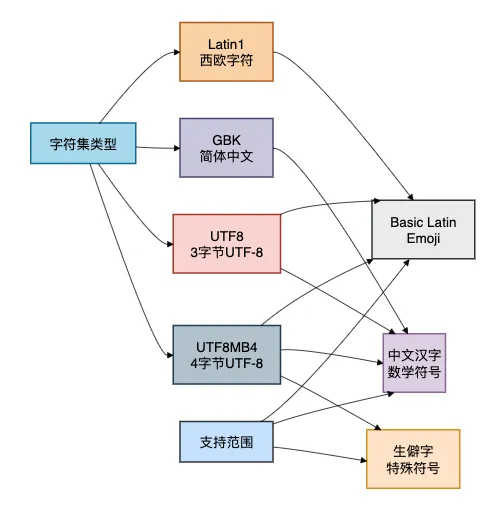
4. 避坑指南:
新项目一律使用utf8mb4字符集
根据业务需求选择合适的排序规则
数据库、表、字段、连接字符集保持一致
迁移现有数据时注意字符集转换